Kubernetes OCT-2022 - Instalando.
Luego de configurar los servidores virtuales, cuentas, instalar paquetes, intentamos arrancar un cluster Kubernetes.
RECORDAR, hacer copia de la maquina virtual para asegurarnos que podemos volver atras si algo falla, kubernetes crea y mantiene ciertos ficheros de configuración que pueden molestar para la instalación posterior. Ante la duda, mejor restaurar la copia ANTES de haber hecho nada con kubeadm.
Para verificar que no tenemos servicios de Kubernetes corriendo, pero SI de Docker. Si vemos puertos asociados a Kubelet o etcd, es una mala señal.
# netstat -tupln
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN 1644/sshd: root@pts
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 604/systemd-resolve
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 2712/sshd: /usr/sbi
tcp6 0 0 :::22 :::* LISTEN 2712/sshd: /usr/sbi
tcp6 0 0 ::1:6010 :::* LISTEN 1644/sshd: root@pts
udp 0 0 127.0.0.53:53 0.0.0.0:* 604/systemd-resolve
udp6 0 0 fe80::a00:27ff:fefe:546 :::* 602/systemd-network
Tratamos de arrancar un nuevo cluster.
# kubeadm init --apiserver-advertise-address=192.168.10.81 --pod-network-cidr=172.16.1.0/16
Pero recibimios este error :
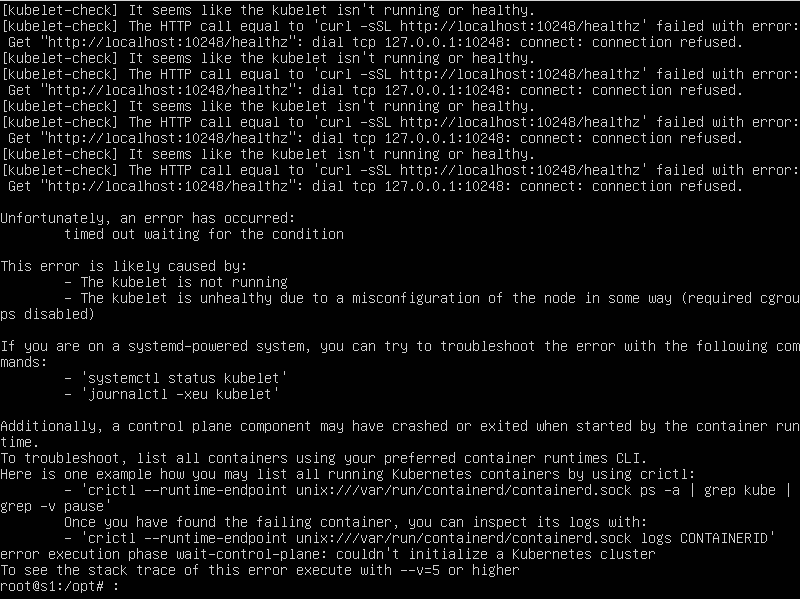
Si al arrancarlo nos da este error “[ERROR CRI]: container runtime is not running:”
sudo rm /etc/containerd/config.toml
sudo systemctl restart containerd
Recomendamos usar equipos físicos que puedan salir a internet sin proxys, sin firewall y si corren estas máquinas virtuales en Windows, revisar firewall de windows. Durante el proceso de instalación bajan imágenes y ficheros de configuración.
En caso de errores, se puede borrar el contenido de la carpeta y relanzar el proceso.
rm /etc/kubernetes -R
Detalle de los puertos que necesitan los nodos.

En caso de identificar este error, borrar el archivo de configuracion y relanzar el INIT.
# luego del init
[ERROR CRI]: container runtime is not running while kubeadm init
rm /etc/containerd/config.toml
systemctl restart containerd
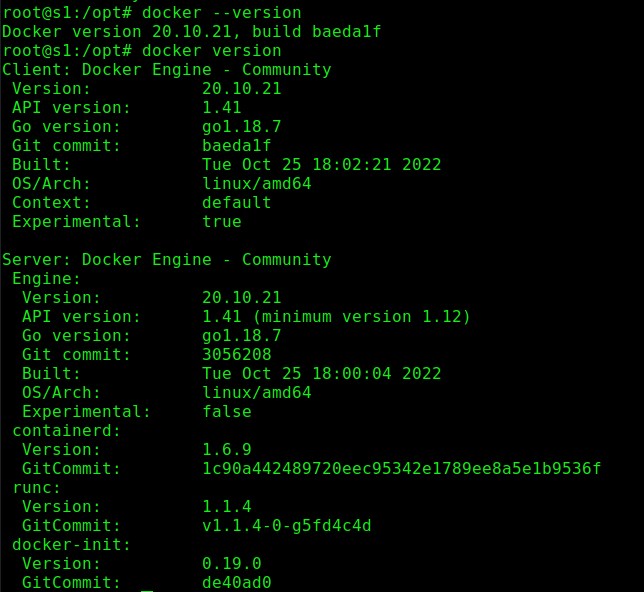
Verificamos las versiones de Servidor y Cliente de Docker.
Descargamos imágenes que necesitaremos en todos los nodos.
# kubeadm config images pull
[config/images] Pulled registry.k8s.io/kube-apiserver:v1.25.3
[config/images] Pulled registry.k8s.io/kube-controller-manager:v1.25.3
[config/images] Pulled registry.k8s.io/kube-scheduler:v1.25.3
[config/images] Pulled registry.k8s.io/kube-proxy:v1.25.3
[config/images] Pulled registry.k8s.io/pause:3.8
[config/images] Pulled registry.k8s.io/etcd:3.5.4-0
[config/images] Pulled registry.k8s.io/coredns/coredns:v1.9.3
Ahora podemos arrancar el cluster.
# kubeadm init --pod-network-cidr=172.200.1.0/24
[init] Using Kubernetes version: v1.25.3
[preflight] Running pre-flight checks
[WARNING SystemVerification]: missing optional cgroups: blkio
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: E1102 20:13:30.631315 941 remote_runtime.go:948] "Status from runtime service failed" err="rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"
time="2022-11-02T20:13:30+01:00" level=fatal msg="getting status of runtime: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
root@s1:/opt# sudo rm /etc/containerd/config.toml
sudo systemctl restart containerd
root@s1:/opt# kubeadm init --pod-network-cidr=172.200.1.0/24
[init] Using Kubernetes version: v1.25.3
[preflight] Running pre-flight checks
[WARNING SystemVerification]: missing optional cgroups: blkio
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local s1] and IPs [10.96.0.1 192.168.10.81]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost s1] and IPs [192.168.10.81 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost s1] and IPs [192.168.10.81 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 17.506825 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node s1 as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node s1 as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: 0jh3ax.qepg32df9dvnvroi
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.10.81:6443 --token 0jh3ax.qepg32df9dvnvroi \
--discovery-token-ca-cert-hash sha256:84c0b47a104c106b75261e5426b4a8bc1bcd2831ee599508a732ed14e323801d
Esta línea es importante porque la tendremos que correr en los demas nodos que asociaremos en el cluster.
kubeadm join 192.168.10.81:6443 --token 0jh3ax.qepg32df9dvnvroi \
--discovery-token-ca-cert-hash sha256:84c0b47a104c106b75261e5426b4a8bc1bcd2831ee599508a732ed14e323801d
Chequeamos los certificados, caducan en 1 año, recordarlo.
# kubeadm certs check-expiration
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Nov 02, 2023 19:15 UTC 364d ca no
apiserver Nov 02, 2023 19:14 UTC 364d ca no
apiserver-etcd-client Nov 02, 2023 19:14 UTC 364d etcd-ca no
apiserver-kubelet-client Nov 02, 2023 19:14 UTC 364d ca no
controller-manager.conf Nov 02, 2023 19:15 UTC 364d ca no
etcd-healthcheck-client Nov 02, 2023 19:14 UTC 364d etcd-ca no
etcd-peer Nov 02, 2023 19:14 UTC 364d etcd-ca no
etcd-server Nov 02, 2023 19:14 UTC 364d etcd-ca no
front-proxy-client Nov 02, 2023 19:14 UTC 364d front-proxy-ca no
scheduler.conf Nov 02, 2023 19:15 UTC 364d ca no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Oct 30, 2032 19:14 UTC 9y no
etcd-ca Oct 30, 2032 19:14 UTC 9y no
front-proxy-ca Oct 30, 2032 19:14 UTC 9y no
Probamos que docker está funcionando correctamente.
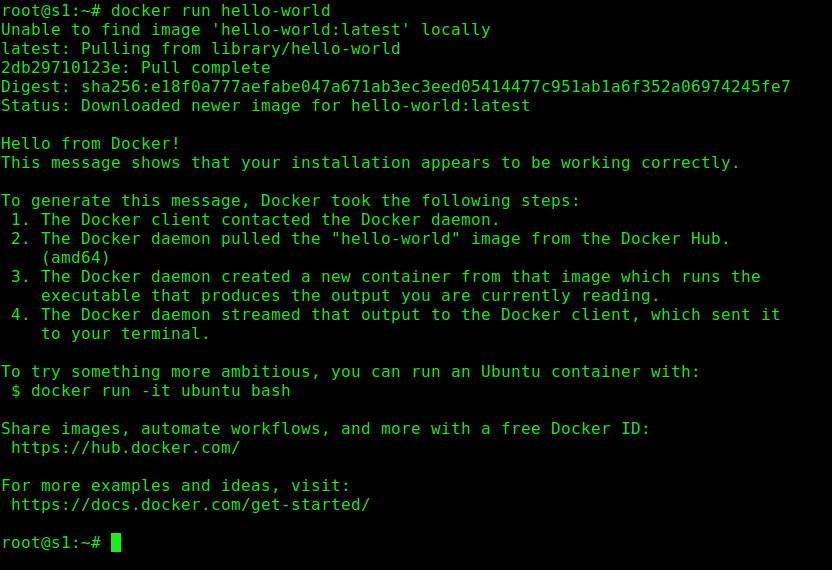
Verificamos los servicios del servidor 1 y los puertos en uso.
# netstat -tupln
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 541/cupsd
tcp 0 0 192.168.10.81:2379 0.0.0.0:* LISTEN 2066/etcd
tcp 0 0 192.168.10.81:2380 0.0.0.0:* LISTEN 2066/etcd
tcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN 850/sshd: root@pts/
tcp 0 0 127.0.0.1:10257 0.0.0.0:* LISTEN 3067/kube-controlle
tcp 0 0 127.0.0.1:10259 0.0.0.0:* LISTEN 3100/kube-scheduler
tcp 0 0 127.0.0.1:10249 0.0.0.0:* LISTEN 3137/kube-proxy
tcp 0 0 127.0.0.1:10248 0.0.0.0:* LISTEN 1761/kubelet
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 565/sshd: /usr/sbin
tcp 0 0 127.0.0.1:44543 0.0.0.0:* LISTEN 994/containerd
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 403/systemd-resolve
tcp 0 0 127.0.0.1:2379 0.0.0.0:* LISTEN 2066/etcd
tcp 0 0 127.0.0.1:2381 0.0.0.0:* LISTEN 2066/etcd
tcp6 0 0 :::6443 :::* LISTEN 2383/kube-apiserver
tcp6 0 0 ::1:631 :::* LISTEN 541/cupsd
tcp6 0 0 :::10256 :::* LISTEN 3137/kube-proxy
tcp6 0 0 :::22 :::* LISTEN 565/sshd: /usr/sbin
tcp6 0 0 :::10250 :::* LISTEN 1761/kubelet
tcp6 0 0 ::1:6010 :::* LISTEN 850/sshd: root@pts/
udp 0 0 0.0.0.0:36008 0.0.0.0:* 479/avahi-daemon: r
udp 0 0 0.0.0.0:5353 0.0.0.0:* 479/avahi-daemon: r
udp 0 0 0.0.0.0:631 0.0.0.0:* 611/cups-browsed
udp 0 0 127.0.0.53:53 0.0.0.0:* 403/systemd-resolve
udp6 0 0 :::5353 :::* 479/avahi-daemon: r
udp6 0 0 fe80::85c4:4df9:95a:546 :::* 484/NetworkManager
udp6 0 0 :::39644 :::* 479/avahi-daemon: r
Verificamos los servicios y puertos de los otros dos nodos. (S2 y S3)
# netstat -tupln
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 537/cupsd
tcp 0 0 127.0.0.1:43693 0.0.0.0:* LISTEN 1093/containerd
tcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN 853/sshd: root@pts/
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 406/systemd-resolve
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 557/sshd: /usr/sbin
tcp6 0 0 ::1:6010 :::* LISTEN 853/sshd: root@pts/
tcp6 0 0 :::22 :::* LISTEN 557/sshd: /usr/sbin
tcp6 0 0 ::1:631 :::* LISTEN 537/cupsd
udp 0 0 0.0.0.0:631 0.0.0.0:* 603/cups-browsed
udp 0 0 0.0.0.0:33519 0.0.0.0:* 475/avahi-daemon: r
udp 0 0 127.0.0.53:53 0.0.0.0:* 406/systemd-resolve
udp 0 0 0.0.0.0:5353 0.0.0.0:* 475/avahi-daemon: r
udp6 0 0 :::58338 :::* 475/avahi-daemon: r
udp6 0 0 :::5353 :::* 475/avahi-daemon: r
udp6 0 0 fe80::7bb1:f827:878:546 :::* 480/NetworkManager
Verificar el cluster.
# kubectl cluster-info
Kubernetes control plane is running at https://192.168.10.81:6443
CoreDNS is running at https://192.168.10.81:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
Al intentar asociar un nodo al cluster nos da este error.
# kubeadm join 192.168.10.81:6443 --token brdwnf.zh3sf63xlpsqzm3p --discovery-token-ca-cert-hash sha256:fb79ea19f435c3c8242172720a5e1d3a7d00b599f72d54a56f0fdcd9037d7563
[preflight] Running pre-flight checks
[WARNING SystemVerification]: missing optional cgroups: blkio
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: E1102 18:35:32.119848 2087 remote_runtime.go:948] "Status from runtime service failed" err="rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"
time="2022-11-02T18:35:32+01:00" level=fatal msg="getting status of runtime: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
La solución aplicada.
cat > /etc/containerd/config.toml <<EOF
[plugins."io.containerd.grpc.v1.cri"]
systemd_cgroup = true
EOF
systemctl restart containerd
Ahora podemos asociar los nodos al cluster, en los nodos s2 y s3 corremos.
# kubeadm join 192.168.10.81:6443 --token 0jh3ax.qepg32df9dvnvroi \
--discovery-token-ca-cert-hash sha256:84c0b47a104c106b75261e5426b4a8bc1bcd2831ee599508a732ed14e323801d
[preflight] Running pre-flight checks
[WARNING SystemVerification]: missing optional cgroups: blkio
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
Luego verificamos en el servidor1 (Admin) los nodos asociados al cluster.
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
s1 NotReady control-plane 12m v1.25.3
s2 NotReady <none> 8m16s v1.25.3
s3 NotReady <none> 17s v1.25.3
En los nodos S2 y S3, tenemos estos servicios.
# netstat -tupln
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 537/cupsd
tcp 0 0 127.0.0.1:43693 0.0.0.0:* LISTEN 1093/containerd
tcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN 853/sshd: root@pts/
tcp 0 0 127.0.0.1:10248 0.0.0.0:* LISTEN 1541/kubelet
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 406/systemd-resolve
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 557/sshd: /usr/sbin
tcp6 0 0 ::1:6010 :::* LISTEN 853/sshd: root@pts/
tcp6 0 0 :::22 :::* LISTEN 557/sshd: /usr/sbin
tcp6 0 0 :::10250 :::* LISTEN 1541/kubelet
tcp6 0 0 ::1:631 :::* LISTEN 537/cupsd
udp 0 0 0.0.0.0:631 0.0.0.0:* 603/cups-browsed
udp 0 0 0.0.0.0:33519 0.0.0.0:* 475/avahi-daemon: r
udp 0 0 127.0.0.53:53 0.0.0.0:* 406/systemd-resolve
udp 0 0 0.0.0.0:5353 0.0.0.0:* 475/avahi-daemon: r
udp6 0 0 :::58338 :::* 475/avahi-daemon: r
udp6 0 0 :::5353 :::* 475/avahi-daemon: r
udp6 0 0 fe80::7bb1:f827:878:546 :::* 480/NetworkManager
En el nodo master, verificamos
# kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-565d847f94-2qx46 0/1 Pending 0 11m
kube-system coredns-565d847f94-gtjnx 0/1 Pending 0 11m
kube-system etcd-s1 1/1 Running 8 (109s ago) 12m
kube-system kube-apiserver-s1 1/1 Running 5 (2m14s ago) 11m
kube-system kube-controller-manager-s1 0/1 CrashLoopBackOff 12 (6s ago) 10m
kube-system kube-proxy-5985n 1/1 Running 1 (43s ago) 49s
kube-system kube-proxy-fb5nw 1/1 Running 1 (53s ago) 56s
kube-system kube-proxy-kzz6z 0/1 CrashLoopBackOff 9 (29s ago) 11m
kube-system kube-scheduler-s1 1/1 Running 10 (105s ago) 10m
Chequeo de las versiones instaladas.
# kubectl version
WARNING: This version information is deprecated and will be replaced with the output from kubectl version --short. Use --output=yaml|json to get the full version.
Client Version: version.Info{Major:"1", Minor:"25", GitVersion:"v1.25.3", GitCommit:"434bfd82814af038ad94d62ebe59b133fcb50506", GitTreeState:"clean", BuildDate:"2022-10-12T10:57:26Z", GoVersion:"go1.19.2", Compiler:"gc", Platform:"linux/amd64"}
Kustomize Version: v4.5.7
Server Version: version.Info{Major:"1", Minor:"25", GitVersion:"v1.25.3", GitCommit:"434bfd82814af038ad94d62ebe59b133fcb50506", GitTreeState:"clean", BuildDate:"2022-10-12T10:49:09Z", GoVersion:"go1.19.2", Compiler:"gc", Platform:"linux/amd64"}
En los nodos que son workers, no podemos interactuar con el cluster.
# kubectl get nodes
The connection to the server localhost:8080 was refused - did you specify the right host or port?
En los tres nodos, habilitar el modo bridge entre las placas, para que pasen los paquetes entre ellas.
echo "net.bridge.bridge-nf-call-iptables=1" |
sudo tee -a /etc/sysctl.conf
sudo sysctl -p
Revisar los componentes.
# kubectl get po -n kube-system
NAME READY STATUS RESTARTS AGE
calicoctl 0/1 Pending 0 8m24s
coredns-565d847f94-2qx46 0/1 Pending 0 35m
coredns-565d847f94-gtjnx 0/1 Pending 0 35m
etcd-s1 1/1 Running 21 (2m31s ago) 36m
kube-apiserver-s1 1/1 Running 15 (4m16s ago) 35m
kube-controller-manager-s1 1/1 Running 28 (104s ago) 34m
kube-proxy-5985n 1/1 Running 7 (10m ago) 24m
kube-proxy-fb5nw 1/1 Running 8 (5m22s ago) 24m
kube-proxy-kzz6z 0/1 CrashLoopBackOff 26 (24s ago) 35m
kube-scheduler-s1 1/1 Running 25 (2m20s ago) 34m
Los nodos nunca se ponían en modo READY, leyendo en internet, parece haber un problema con la red.
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yaml
# Finalmente despues de horas de investigacion, ahora funcionan.
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
s1 Ready control-plane 62m v1.25.3
s2 Ready <none> 58m v1.25.3
s3 Ready <none> 50m v1.25.3
Para gestionar la red de los PODs hace falta instalar un plugin adicional, hay varios pero usaremos el del CALICO.
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
Este parámetro dicen que hay que ponerlo para que en cada arranque el usuario pueda invocar a las herramientas cliente.
# copiar la configuración de Kubernetes
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# Agregar la configuración
export KUBECONFIG=/etc/kubernetes/admin.conf
.